Announcing Matrix XII: An $800M fund to invest from concept to Series A Read more


Large language models (LLMs) are excellent next-word predictors, and typing the next word faster literally means getting more done as a software developer. As a result, autocomplete is currently the dominant LLM application in programming.
As large language models get better at reasoning tasks, what new developer paradigms and interfaces can we imagine?
Here are a few major themes currently guiding my thinking and investing.
LLMs present a path to using natural language as a programming abstraction. The history of programming is a march towards more powerful and higher-level abstractions. First, we programmed in binary, then assembly, then higher-level languages like Fortran that preceded the languages we take for granted today, like Python and Javascript.
Each new abstraction tries to move programming forward by lowering the skill floor or raising the skill ceiling. Natural language primarily lowers the skill floor for programming. This is great because anyone can get started with programming. However, natural language may not be the best abstraction for tasks with a high skill ceiling.
Consider the following two programming prompts:

In the first example, the LLM would likely make some assumptions and infer what data type this function should accept. The second is more precise, leaves little room for interpretation, and is likely written by someone who has been burned one too many times, playing fast and loose with data types.
The first example has what I call a high gap tolerance: the user is likely okay with LLMs closing any gaps they failed to specify. Natural language is an excellent abstraction in this case.
At a sufficient level of complexity, however, gap tolerance becomes so small that you must specify too many details of your natural language prompt. Details that you often didn't know existed until you started to program.
How might we solve this?
We can always revert to using a formal abstraction — this is likely the answer for most complex programming tasks where gap tolerance is small.
Alternatively, we can imagine a world where our programming environment changes to account for gap tolerance. Imagine an IDE that can infer gaps in your prompt and ask you questions about your prompt. Oh... you want a function that adds two numbers? Tell me more. Are these numbers currencies or basketball scores?
This is just one example of how natural language as an abstraction will change how we program and the environment in which we program.
The critical point is that we must distinguish between programming skill and the symbolism — formal or natural language — used to do programming. The former is not going anywhere. The latter is evolving, and this evolution gives us several tools to pick from when programming.
Compilers transformed developer productivity as developers no longer had to write machine code or assembly. They could program in a higher-level language, and compilers would translate their source code into target code for some architecture or another higher-level language. This works as far as there exists a compiler for that source-target combination.
LLMs further extend this concept. We can think of them as universal compilers for any source-target combination. Compiling from source to target can be treated as a translation task. What can we do with a universal compiler?
Any code transformation task could benefit from this:
All of these tasks fit a similar spec:
The above spec provides the recipe for several tasks developers do today that they no longer have to pay attention to.
Programming today is procedural. You give a computer a set of instructions to follow, and it dutifully executes. What if, instead, we simply specify the outcome we want and what constraints we would like to impose? The computer then figures out the how.
This idea of goal-oriented programming has existed for a while but has struggled to take off. One of the earliest examples is a language called Prolog from the 70s. In Prolog, you first encode a set of rules. Afterward, any computation is expressed as a goal inferred from those rules.
Suppose Prolog is encoded with a rule: plants are green. If you specify a goal: give me something green. Prolog returns: plant.
Prolog had to encode knowledge via rules. At the time, we didn’t have a way to train large language models on vast data. Today, goal-oriented programming seems more tractable.
Here is Open AI CTO, Greg Brockman, demoing something that echoes Prolog from 1972. In this example, GPT-4 generates working HTML code from a hand-drawn sketch. The sketch is the goal, and GPT-4 figures out the correct procedures — HTML code — to achieve that goal.
Not having to write programs as sequential procedures seems like a big deal. At a bare minimum, problem specification — the what of programming — becomes far more critical than symbol manipulation — the how of programming.
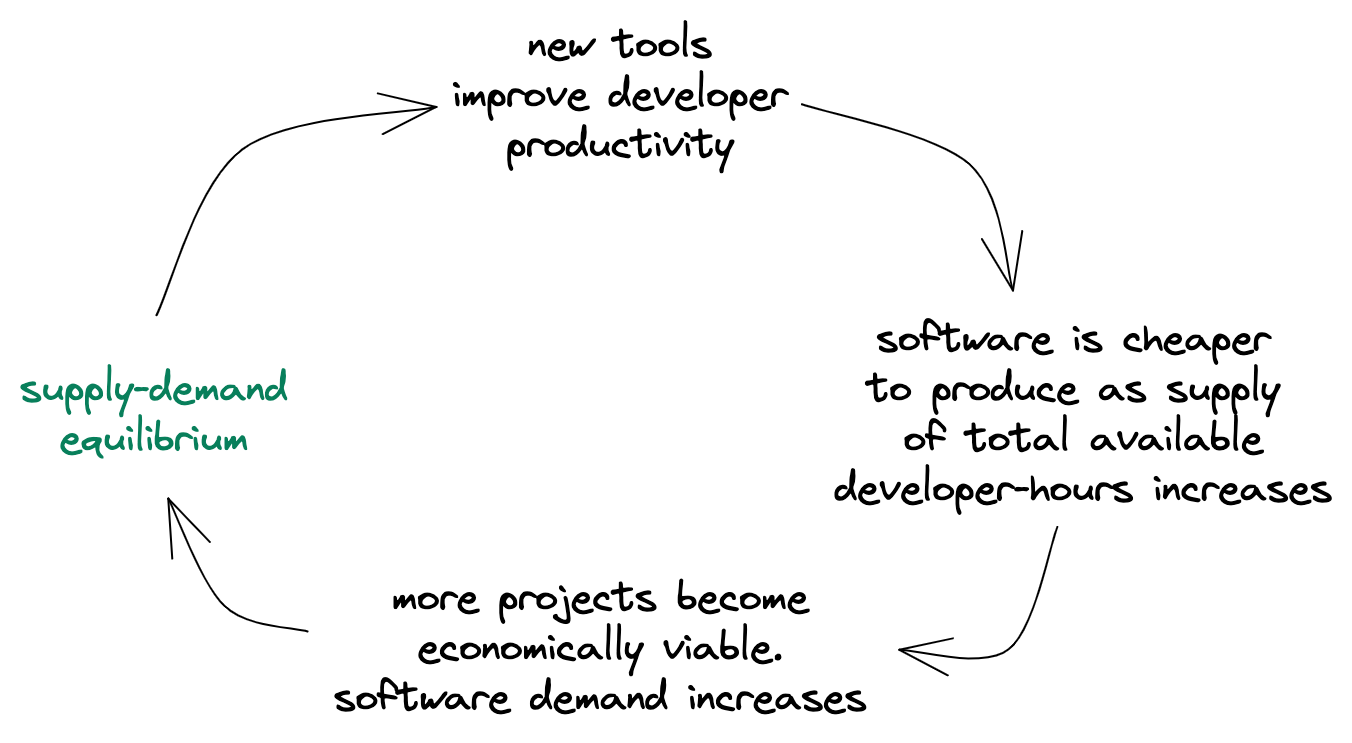
The fear-mongering about the demise of software engineering misses a key point: supply-demand equilibrium in software engineering happens remarkably fast.

First, developers become more productive as their tools get better. Next, the cost of producing software decreases overall. Consequently, more projects become economically viable, leading to an explosion in demand for software. The net effect is that as it gets easier to build software, even more software is built. We never quite catch up to the flood of new supply due to increased efficiency.
The end of programming is greatly exaggerated. There’s never been a better time to be a developer or to be building for developers.